
Written by Aditi Choudhary
As a multidisciplinary field, Data Mining focuses on uncovering hidden patterns within data sets, with Machine Learning serving as a key approach in this exploration. Machine Learning, a branch of data science, is devoted to creating algorithms that can learn from data and make accurate predictions. The growth of e-commerce has led to an overwhelming amount of information for users, often making it difficult to locate content that matches their preferences. To address this challenge, a system has been developed that uses user’s purchase histories to recommend similar food products, taking into account their daily health conditions. Machine Learning algorithms, such as Support Vector Machine (SVM) and Random Forest, were utilized and compared in this context. The analysis revealed that SVM outperforms Random Forest in terms of effectiveness, highlighting its superior performance for this application.
Introduction
The internet has revolutionized the landscape of commerce, ushering in the era of online shopping and transforming traditional trading behaviors. This evolution has paved the way for advanced web applications known as Recommendation Systems, which are designed to predict user preferences. These systems provide personalized suggestions to online shoppers by predicting potential purchases based on past buying history. In a recent study, a Recommendation System was developed specifically for online food product e-commerce websites. Nutrient datasets and user-specified health issues were utilized to recommend suitable food products. By implementing Machine Learning algorithms such as Support Vector Machine (SVM) and Random Forest, the system maps health conditions to the nutritional content of various foods globally, offering tailored recommendations to users. Rigorous analysis revealed that SVM outperformed Random Forest in accuracy. This innovative method not only addresses health-related dietary needs but also represents a significant advancement over traditional Collaborative Filtering techniques, which often face challenges with data sparsity and compatibility issues.
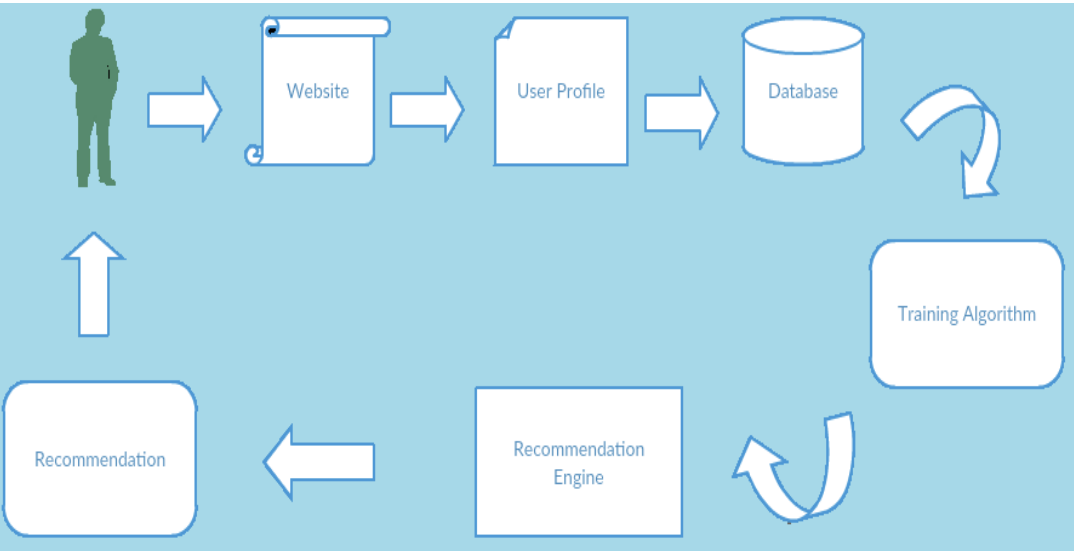
Working of the recommendation system
The Recommendation System Architecture follows these steps: When a food product is to be purchased on the e-commerce website, a user profile must be created if it is the user’s first visit, specifying any health issues. This information is stored in the database along with the ingredient dataset. The dataset is processed by the training algorithm and then fed into the recommendation engine. This data is used by the recommendation engine to predict and suggest food products similar to those previously purchased by the user, tailored to their health condition.
Recommendation system with Support Vector Machine
The Support Vector Machine (SVM) algorithm was utilized to predict and recommend similar food products based on items previously purchased by the user. Support Vector Machines, which are supervised learning models, were employed for classification and regression analysis. The classification categories include “Highly Recommended,” “Recommended,” “Least Recommended,” and “Avoid,” with these classifications applied to products based on the user’s health conditions, such as Diabetes, Stroke, Gall Bladder issues, Arthritis, and Bronchiectasis. The training data for the SVM module was divided with 60% used for training and 40% for testing. The algorithm, developed in Python, employs a fuzzy set approach to classify products. This approach converts data into fuzzy variables, allowing for flexible thresholds. For instance, instead of categorizing a product with 7.2 grams of carbohydrate as strictly high or low, fuzzy logic enables a more nuanced classification. It allows for a range where 7.15 grams might be considered somewhat high but not as high as 7.2 grams. Fuzzy logic is used to determine appropriate recommendations for individuals with health conditions like Diabetes, where the maximum sugar intake is set at 7 grams and fat content at 4 grams. The fuzzy set membership function is applied to segregate food items based on their nutrient content.
The products are classified as soon as the algorithm, implemented in Python, is run. According to the formula shown in Figure-3, a fuzzy variable function assigns a degree of 1 if the difference between the maximum limit and the fat or sugar content is significant, categorizing the product as “Highly Recommended.” If the difference falls within a range between 0 and 1, the product is classified as “Recommended.” A degree of 0 indicates that the margin is low, and the product is classified as “Least Recommended.” If the degree is -1, the product’s fat or sugar content is excessively high, placing it in the “Avoid” category.

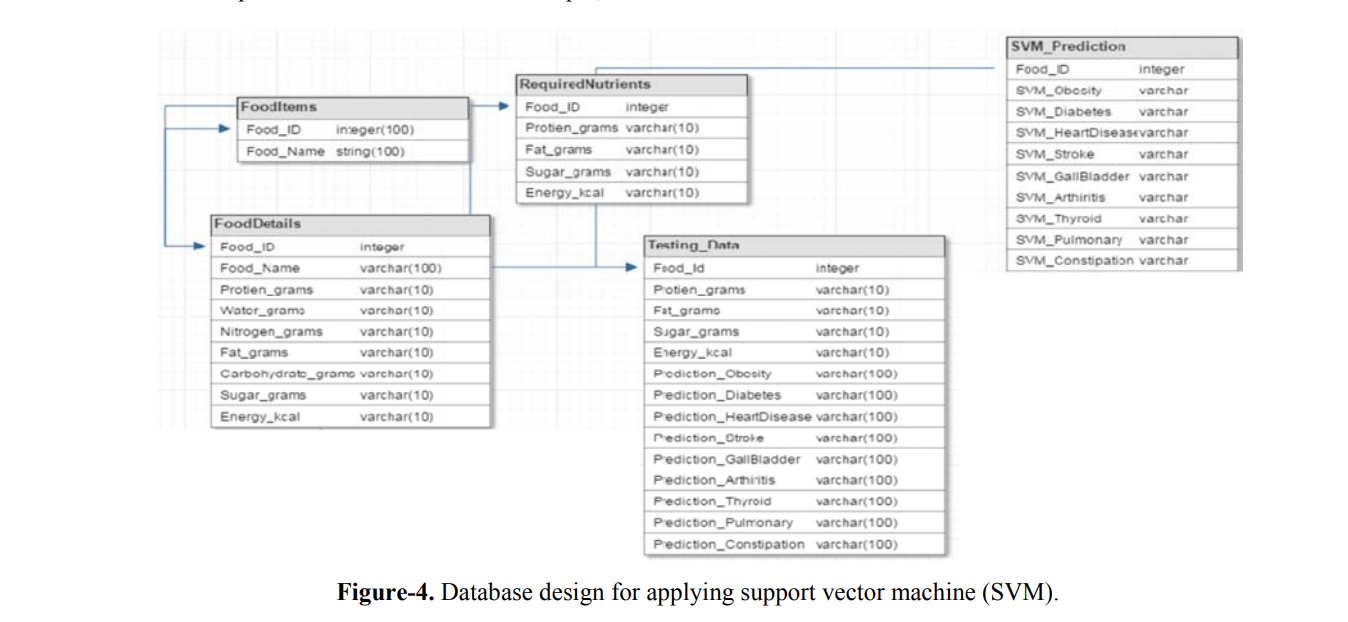
Using these classifications, the training set is processed and used to train the SVM module, which then classifies the remaining data. The results are stored in a database. When a specific product is selected by a user, similar products are retrieved from the database and the best match is displayed based on the classification. For instance, if Yogurt is selected, all yogurt products are filtered, and the one categorized as “Highly Recommended” is shown. If no “Highly Recommended” products are available, the next best classification is chosen, continuing until an “Avoid” product is reached. The database schema, illustrated in Figure-4, includes the “FoodItems” table with food product IDs and names, the “FoodDetails” table with nutrient values, and the “RequiredNutrients” table, which specifies the nutrients considered in the “Testing_Data” table. From the “SVM_Prediction” table, users receive recommendations for food products that are beneficial to their health and best suited to their needs.
Recommendation system with Random Rainforest
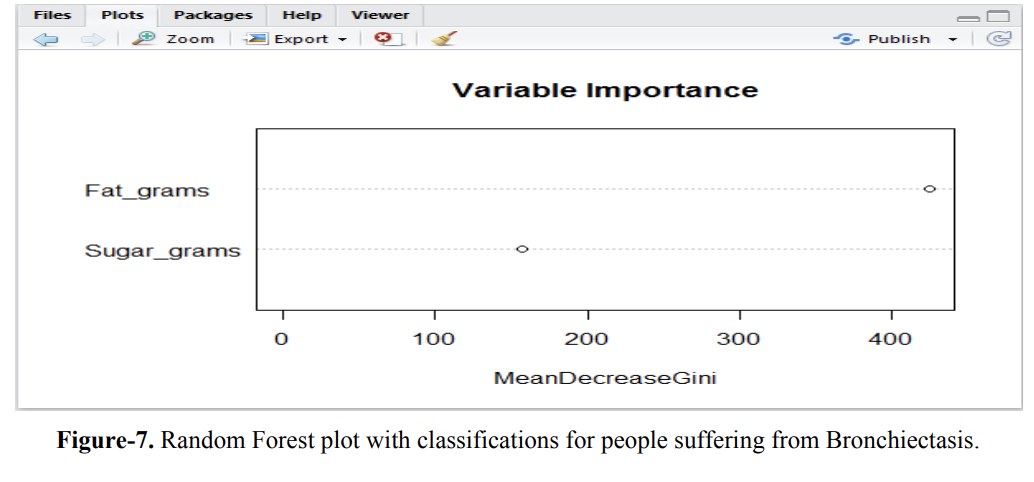
The Random Forest algorithm is utilized to classify data through a multitude of decision trees. This method generally takes about twice as long to execute as SVM due to the creation and processing of multiple trees to reach a conclusion based on the training set. The fuzzy set approach is used to train the dataset, and the Random Forest module in R Programming employs this approach to classify data into categories such as “Highly Recommended,” “Recommended,” “Least Recommended,” and “Avoid.” After classification, the predicted values are stored in a table, which is then used to recommend products to users. When a product is specified for purchase, a list of similar products is retrieved. For the prediction approach, two factors are focused on for classifying products for individuals with Bronchiectasis: sugar content and fat content. The Random Forest approach generates a plot to illustrate these classifications.
Figure-7 clearly shows that fat content is given more importance than sugar content in the prediction process. If no products fall into the “Highly Recommended” category, the next best classification is selected until reaching the “Avoid” category. The database design for this process mirrors that used for the SVM algorithm, with the sole difference being the use of the “RandomForest_Prediction” table instead of the “SVM_Prediction” table, while retaining the same attributes.
Comparison Between Support Vector Machine (SVM) and Random Forest
The SVM approach is generally found to outperform Random Forest in terms of accuracy. This is determined by applying fuzzy set variable logic to various testing models and comparing the results with the trained model. In the analysis, the testing model includes 875 food products, while the trained model encompasses 1,200 food products, totaling 2,075 records. The Random Forest algorithm took more time to execute compared to the SVM approach. The time complexity of SVM is O(max(n,d) min (n,d)^2), where n is the number of points and d is the number of dimensions [16], and that of the Random Forest is O(v * n log(n)), where n is the number of records and v is the number of variables/attributes. Accuracy is assessed by comparing the predicted data with the trained data.
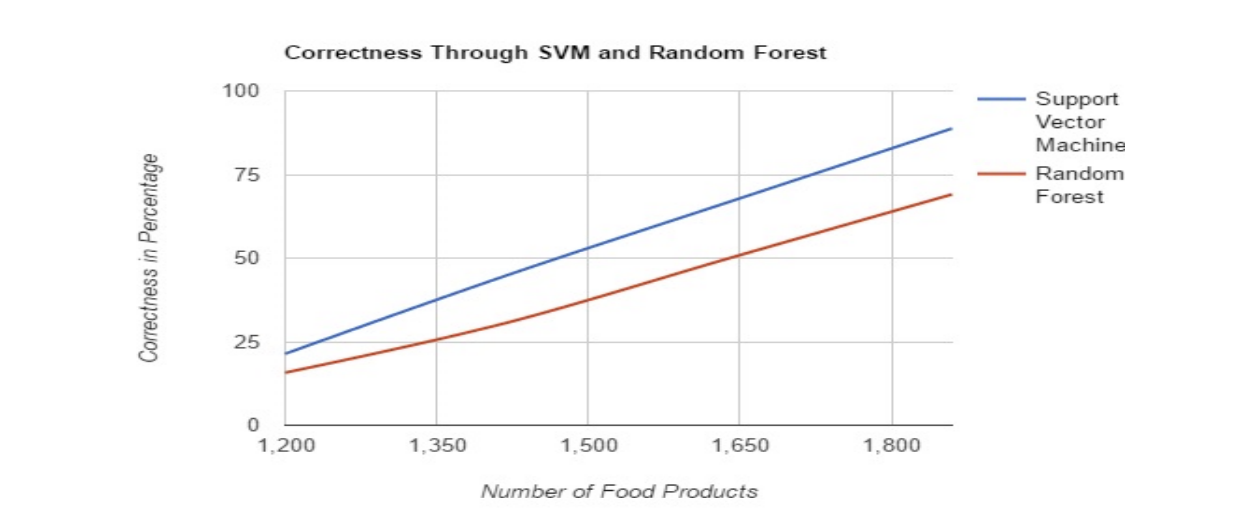
The accuracy percentages for product recommendations using SVM for patients with Diabetes, Stroke, Gallbladder disease, and Bronchiectasis were 88.45%, 89.37%, 85.71%, and 81.74%, respectively. In comparison, Random Forest achieved accuracies of 74.97% for Stroke, 50.51% for Gallbladder disease, and 81.71% for Bronchiectasis. Overall, SVM provided an accuracy of 88.77%, while Random Forest’s accuracy was 69.07% for predicting untrained and varied models. Additionally, the SVM approach executed in 1.38 seconds, whereas the Random Forest approach took 2.388 seconds. The research concludes that SVM significantly outperforms Random Forest in predicting testing datasets, making SVM the better choice for providing more accurate recommendations.
References
[1] https://www.arpnjournals.org/jeas/research_papers/rp_2017/jeas_1017_6376.pdf
[2] http://infolab.stanford.edu/~ullman/mmds/ch9.pdf
[3] http://sci2s.ugr.es/keel/pdf/specific/congreso/xia_don g_06.pdf
[4] P. Jonathon Phillips: 1998. Support Vector Machines Applied to Face Recognition. NIPS 1998: 803-809.
[5] T. Joachims. 1998. Text categorization with support vector machines. In European Conference on Machine Learning (ECML).
[6] Olivier Teytaud, David Sarrut: Kernel- Based Image Classification. ICANN 2001: 369-375
[7] Ko-Jen Hsiao, Alex Kulesza, and Alfred O. Hero. 2014. Social Collaborative. IEEE Journal of Selected Topics in Signal Processing. 8(Disease: 4).
[8] D. Dubois and H.F’rade. 1990. Fuzzy Sets and System; Theory and Applications. New York: Academic.
[9] http://nutritiondata.self.com.
[10] https://en.wikipedia.org/wiki/Support_vector_machine.
[11]https://en.wikipedia.org/wiki/Random_forest.
[12]http://www.cmaj.ca/content/suppl/2013/02/19/cmaj1

















{kind=link}