

ARPA-H, part of the National Institutes of Health, is actively addressing the challenges posed by the widespread use of Large Language Models (LLMs) in healthcare, which have encountered significant hurdles due to safety and reliability issues, notably the occurrence of hallucinations—where chatbots produce incorrect or misleading information. These inaccuracies present a major barrier to deploying medical chatbots capable of reliably providing health information. To tackle these issues, ARPA-H has launched the CARE initiative, a focused 24-month program that aims to develop innovative technologies to evaluate AI chatbot outputs efficiently and at scale, ultimately aiming to match the accuracy of human experts.
By enhancing the trustworthiness and utility of medical chatbots, ARPA-H aims to significantly advance healthcare technology. The CARE ET project specifically targets the creation of tools that combine computational speed with human-level precision. This initiative seeks to make health information more reliable and accessible, particularly for underserved communities who often face significant obstacles in accessing accurate health information online. The development and implementation of these evaluation technologies are crucial for improving how medical information is delivered and accessed through digital platforms.
The 24-month project divided into three stages, where participants need to use their resources wisely to develop the capabilities outlined in each technical area (TA). Proposals must meet the requirements for each TA subsection across all three stages. The total budget for this project is capped at $8 million. The budget for each stage is as follows: Stage I (covering both TA 1.1 and 1.2) has a maximum budget of $1.8 million, while Stage II and Stage III (each covering TA 1.1 and 1.2) have a budget cap of $3.1 million per stage.
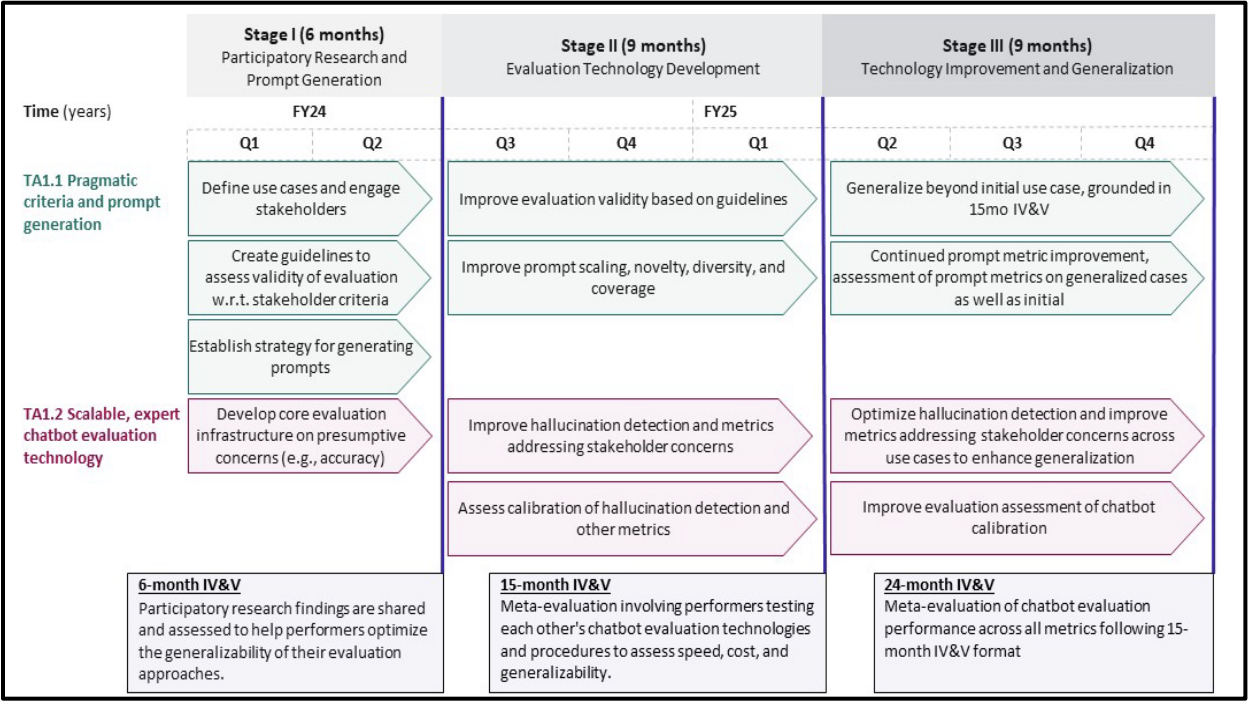
The CARE initiative is strategically structured into two key subsections within a singular technical area, focusing on both the generation of prompts and the evaluation of chatbot responses. The first subsection, TA1.1, is dedicated to improving prompt generation technology. This involves aligning medical chatbots with clinical and societal values through comprehensive stakeholder engagement, including patients, caregivers, and health professionals. The goal is to generate diverse and relevant prompts that reflect a wide range of stakeholder desires and concerns, which will help in systematically identifying and mitigating potential harms, such as bias and misinformation that exacerbate health disparities.
The second subsection, TA1.2, focuses on developing scalable technologies that can detect factual hallucinations with high accuracy. These technologies are designed to evaluate a large number of chatbot outputs swiftly, combining the precision of expert human assessments with the efficiency of computational methods. Proposals for TA1.2 must describe scalable evaluation technologies that can perform these functions while also being capable of generalizing across different patient-facing medical chatbot applications, thus ensuring the solutions developed can be broadly applied to enhance the reliability and safety of medical chatbots in diverse healthcare settings.
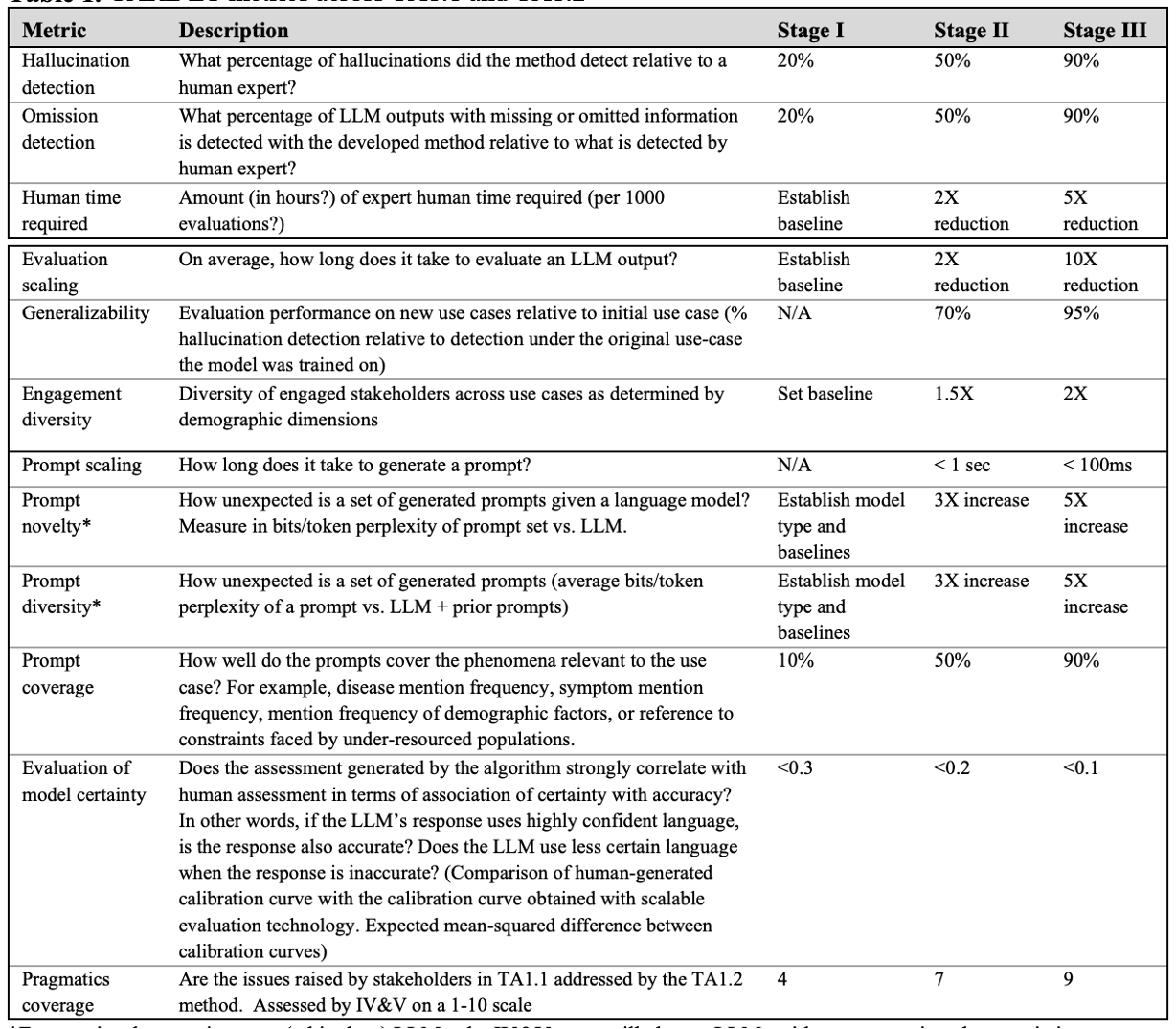
Overall, through the strategic development of the CARE initiative, ARPA-H hopes to bridge the gaps in digital health communication, ensuring that all users, regardless of their background, have access to timely and accurate medical advice. This initiative could greatly enhance public health by providing enhanced digital means for medical advice, thus helping to ensure that healthcare becomes more inclusive and effective. By addressing the challenges of hallucinations and other inaccuracies in LLMs used in healthcare, ARPA-H is paving the way for more dependable medical chatbots, transforming how health information is perceived and acted upon across the nation.
One example of how the above effort could be implemented for a psychiatrist chatbot is below.
The process would start by training a chatbot, such as a psychiatrist chatbot, using specific information like mental illnesses identified by the American Psychiatric Association (APA) using DSM-5, is generally referred as retrieval augmented generation (RAG).
Here is an example interaction with a chatbot based on mental illnesses defined in DSM-5:
Patient: I’ve been feeling really down and hopeless for the past few weeks. I don’t enjoy my hobbies anymore.
Medical Chatbot Response:

At this stage, a human evaluator would review the questions and answers, then grade each response with a thumbs up or down, indicating how well the chatbot performed compared to how they would respond to similar questions. This process could be repeated by multiple human evaluators, and their ratings could be summarized in a dashboard similar to the one shown below.
This human feedback loop allows government evaluators to grade various chatbot models. Developers can use this feedback to refine the model, adjust the prompts, or modify the source data until the desired positive response score is achieved. While the above example uses OpenAI, various medical large language models (LLMs) could be used instead of OpenAI’s generic models.
To create a similar chatbot using your organization’s own data visit Dropchat.



















{kind=link}